

Productionizing State-of-the-Art Models at the Edge for Smart City Use Cases (Part I)
Approaches to productionizing models for edge applications can vary greatly depending on user priorities, with some models not requiring model optimization at all. An organization can choose pre-existing models designed specifically for edge use cases with performance compromises compared to their heavier-weight but better-performing counterparts, if ease of deployment is a priority. For example, a set of models tailored to a Raspberry Pi will be much more lightweight because they are optimized with the hardware restrictions in mind, but this isn’t ideal if you need to run a model designed for a unique purpose that demands specific performance.
Typically, organizations work with tradeoffs (e.g. performance vs. ease-of-use) to work around their needs and priorities.
In the context of Smart Cities—where model performance at the edge determines the quality of the city experience (e.g. improved user experience)—ensuring performance integrity is a non-negotiable requirement. The desire to maintain model flexibility and performance on a wide variety of hardware platforms creates conflicting trade-offs: performance vs. resource-efficiency; complexity vs. scalability; latency vs. accuracy; among others. Without an in-depth knowledge in both the software and hardware-side of productionizing edge AI applications, reconciling these conflicting needs can present a substantial operational challenge.
With the right solution, however, balancing these trade-offs doesn’t have to be a case of being stuck between Scylla and Charybdis.
In this blog, we will explore how well-optimized models enable reliable, efficient, and real-time performance-ready edge AI for Smart Cities, improving traffic management, public safety, environmental monitoring, and more.
Here’s how we define what high-quality intelligence at the edge means for driving reliability, efficiency, and real-time performance:
- Reliability: No degradation in model performance post-compression/optimization
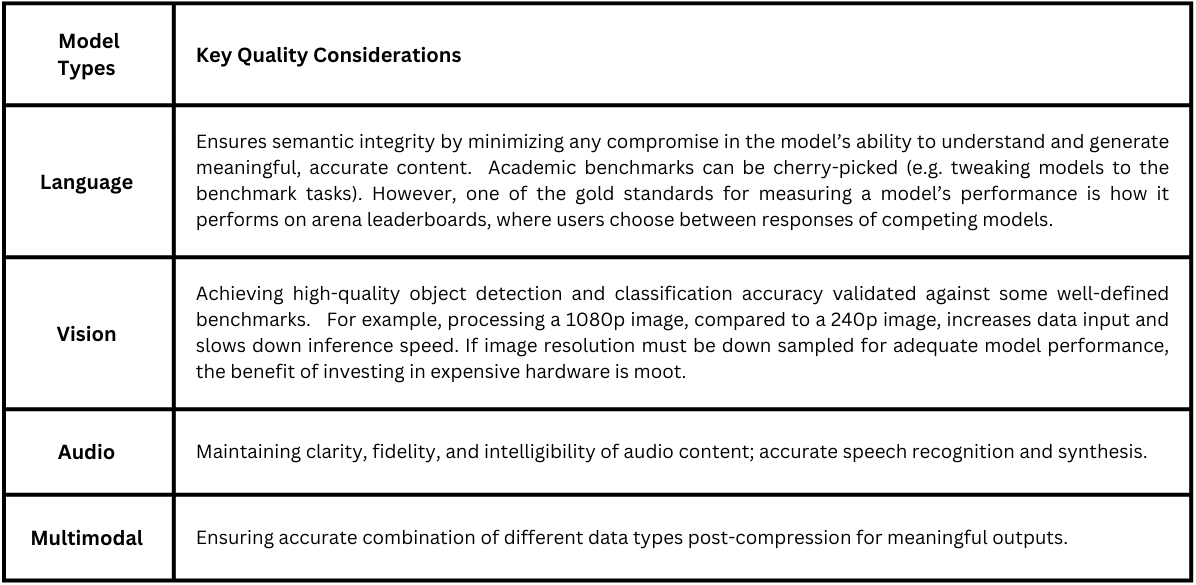
- Efficiency: Reduced resource consumption (compute, memory, power) without significant performance degradation.
- Real-time performance: Faster inference time and low latency compared to the original model, enabling immediate responses and real-time decision-making at the edge.
Having defined what “good model performance” means in the context of a variety of Smart City-applicable models, we will now transition to the question of how to achieve it.
Typically, before technology gets adopted in production, it begins as a small pilot project, then undergoes testing, refinement, and preparation for scaling. During the early stages of planning, it’s worth defining the project’s scope in terms of measurable goals. But equally important is understanding the sector vertical's specific landscape and its interaction with software and hardware components to better anticipate project outcomes.
Smart Cities, characterized primarily by the physical constraints of their environment, present distinct challenges compared to, let’s say, the finance sector, where server-side applications emphasize the importance of AI-application speed and data center infrastructure availability. Embedding intelligence for Smart City initiatives, on the other hand, requires significant logistical efforts, including physical device installations and ongoing maintenance (e.g. regular onsite visits).
City-Centric AI for Seamless and Sustainable Integration of Intelligence
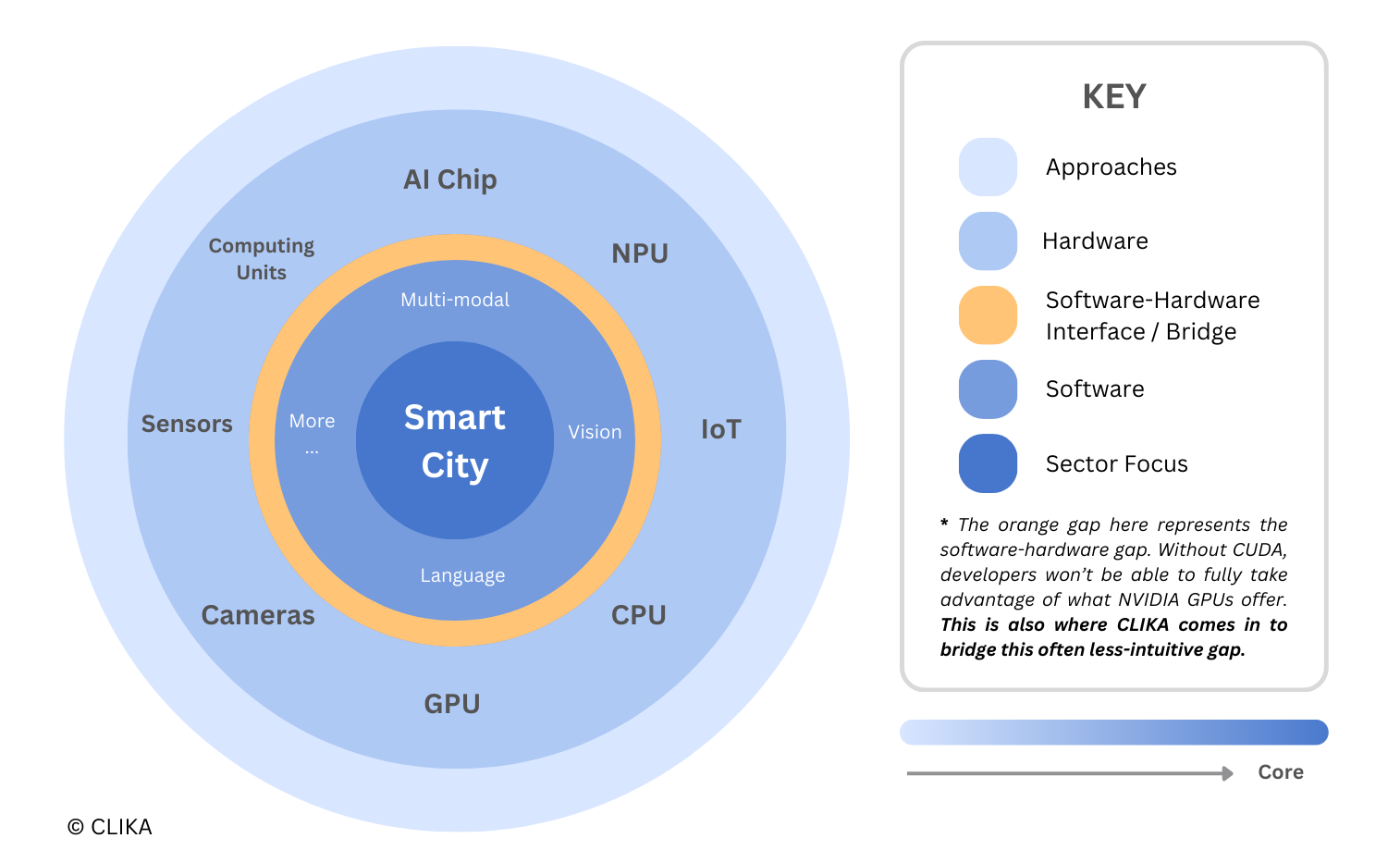
- Understanding the hardware landscape in urban areas: To give a concrete example, city projects aiming to monitor and analyze traffic flows at intersections use a combination of various vision models (e.g. object detection, super resolution). Because the existing hardware landscape often varies throughout the city, ranging from low-power antiquated cameras to more capable edge devices, tiered deployment and model compression strategies are necessary to run these models as a unified software pipeline in production. Bottom line, you need to deploy the same model across multiple hardware platforms. But hardware presents varying restrictions.
- Understanding the hardware restrictions:
- Software compatibility: Each device offers varying support for operators and modules. An example is a model deployed on NVIDIA GPUs will not be performant or compatible with a powerful CPU that doesn’t have NVIDIA hardware. Even within the NVIDIA ecosystem, architectural and driver differences can prevent model compatibility across GPUs. Recognizing these hardware restrictions, we developed our solution to ensure model interoperability across diverse hardware platforms.
☛ Check out our benchmarks to see how effectively CLIKA-compressed models perform on a variety of devices, here
Coming soon: benchmarks for LLMs on edge devices!
- Memory and Resource Constraints: Running computationally demanding models on devices with limited RAM and other resources (e.g. power budgets, processing power, etc.) leads to slower processing times, crashes, and/or thermal throttling. Because of its potential impact on real-time performance, lowering a model’s memory footprint is crucial to avoiding these undesirable outcomes. Quantizing the model to lower bit precision presents a solution, but vendor optimization solutions come with non-negligible accuracy loss, forcing a trade-off between memory-efficiency and the accuracy required for production-grade use.
☛ CLIKA’s quantization schemes are of two types: quantization-aware-training (QAT) and post-training-quantization (PTQ), and our implementations of both these schemes do not compromise accuracy.
* We’ll delve into the feature set of each in a later blog post.
- Software compatibility: Each device offers varying support for operators and modules. An example is a model deployed on NVIDIA GPUs will not be performant or compatible with a powerful CPU that doesn’t have NVIDIA hardware. Even within the NVIDIA ecosystem, architectural and driver differences can prevent model compatibility across GPUs. Recognizing these hardware restrictions, we developed our solution to ensure model interoperability across diverse hardware platforms.
- Understanding the software component (model architecture, specifically): While not always the case, model performance typically improves with increased size and complexity. But unlike the rigid constraints of hardware, working with AI model architecture allows for a relatively large margin of flexibility for optimization and hardware-centric adaptation. For example, compressing heavyweight models accelerates inference speed due to reduced computational complexity, enabling real-time performance.
☛ With CLIKA’s solution, organizations can expect up to 12 times the original inference speed and up to 87% smaller models—boosting memory efficiency and inference speed.
Integrating CLIKA’s Solution for Seamless Compression and Deployment
Our toolkit automatically compresses a range of models, even proprietary ones on-premises, for seamless deployment across various hardware platforms, driving scalability, faster time-to-market, and resource efficiency; interoperability with different hardware makes embedding intelligence into varied city landscapes effortless.
Hardware-locked dependencies: no longer a barrier with CLIKA⚡
Hardware is a capital-intensive investment, and the upkeep of infrastructure can be even costlier for organizations with budget quotas. Without long-term incentives to upgrade, the hardware often remains a static investment. As a result, both past and current practices have relied on making models hardware-dependent, aligning them with existing infrastructure’s capacity and tailoring the models to fit its limitations and specifications. Because optimizing models without adequate experience often leads to significant performance degradation unfit for production-grade use, it is typically done selectively or completely left out altogether, opting instead for a smaller model.
However, this approach represents an opportunity cost because it prevents the organization from fully unlocking what the model could have been had it not been for these hardware constraints. The growing complexity and computational demands of today’s AI models are making this opportunity cost increasingly evident.
For Smart City uses cases involving edge AI, our toolkit decouples model deployment from hardware dependencies, emphasizing model adaptability and efficient software integration—all without compromising performance integrity.
We will continue to delve further into this topic in part 2 of this blog series.
To learn more about our solution, contact us!

){kind=link}