

In My Biased Opinion Recap: Inference Optimization
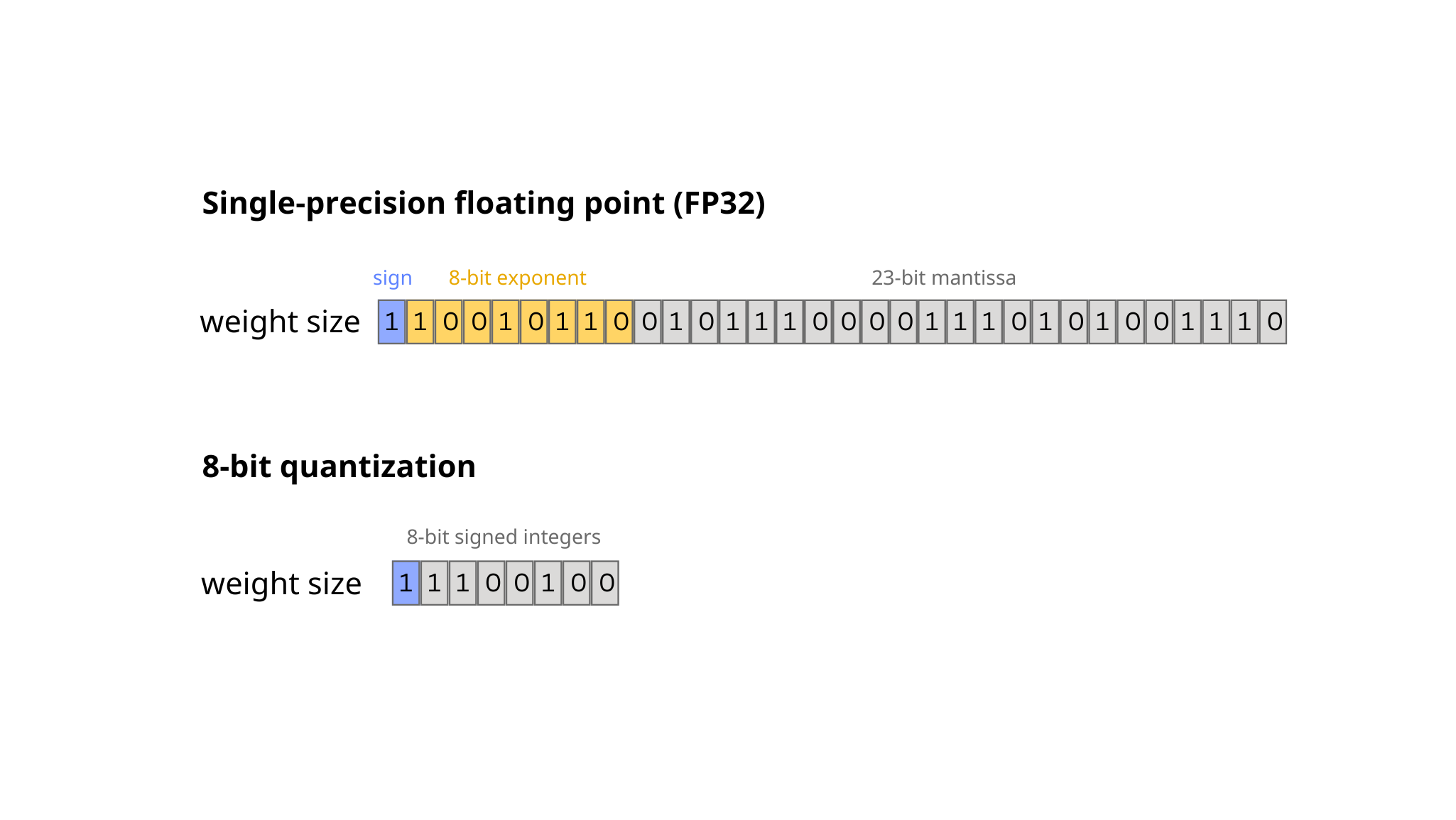
From static quantization to quantization-aware training, the quantization techniques to make your AI models lightweight for accelerated inference are growing. Quantization typically involves engineers converting a model to a representation with a reduced number of bits, usually integers, instead of using full-precision, floating-point model data to accelerate the speed of model computations. Specifically, to quantize is to transform as much of the model as possible to integer data and computations, which tend to be fast, and to minimize the parts of the model that use floating point data and operations, which tend to be slow. This is because floating point data requires more memory and computation to process, as can be seen in the image below (figure 1). As a result, quantizing as much of the model as possible typically results in better inference performance and speed.
Figure 1. Quantization in a nutshell
For ONNX models, a common intermediate storage format, when determining how you want to represent the quantized models, Ben prefers the tensor-oriented approach as opposed to the operated-oriented approach.
This is because if you opt for the operator-oriented approach, the graph compiler may not be smart enough to recognize a quantized operator, such as QLinearConv—the quantized version of the convolution operator commonly used in computer vision models. The tensor-oriented approach, on the other hand, allows for more control over the graph compiler output in that if your model contains a convolution layer (Conv) and a QDQ (quantize and de-quantize) node, the QDQ node acts as a hint for the graph compiler to fuse them and quantize the entire operator.
Jungmoo, however, points out that with great power comes great responsibility, and depending on where the QDQ nodes are placed before graph compilation, the compiled model may actually perform more slowly than the original model.
But the main idea is that we are doing these optimizations for accelerated inference speed, and it is important to ensure the optimized model’s compatibility with the appropriate target hardware. In other words, the hardware needs to support the operations required by your chosen quantization scheme for your model—a step that is often overlooked by many model users in practice.
Most people casually develop models on a desktop or server-side environment without considering their compatibility with the target hardware for deployment, only to realize that their models do not perform optimally or efficiently on the chosen hardware, achieving poor accuracy and/or inference speed. See the flowchart below for surface-level elaborations:
Figure 2. A flowchart outlining a potential problem (surface-level)
GOAL:
John, a data scientist, plans to develop a real-time object detection system for a retail store’s security cameras (edge device) to monitor any suspicious activities.
↓
DEVELOPMENT:
John decides to work with YOLOv5 due to its claimed performance. After extensive model training and fine-tuning, the model achieves high accuracy and fast inference times on the desktop.
↓
DEPLOYMENT:
John goes for NVIDIA Jetson Nano devices for their design for edge AI applications and affordability.
↓
PROBLEM 1:
But Jetson Nano has significantly less computational power than the desktop's high-end GPU
↓
PROBLEM 2:
When John transfers the trained YOLOv5 model to Jetson Nano, several issues arise, but not limited to:
• Poor inference speed: Jetson Nano struggles to perform inference at the required speed and efficiency.
• High memory requirement: The model's memory requirement exceeds what Nano can support
• Suboptimal performance: Nano's less powerful GPU fails to handle the model with the same level of computational efficiency
↓
SOLUTION:
John notices these problems and decides to spend another 4-5 months light-weighting the model or switching to a smaller model like Tiny YOLO and retraining it.
At CLIKA, we have created a seamless tool that can handle all of these considerations for you in order to achieve great performance, from model compression to hardware deployment. See the full video below to learn more.


{kind=link}